Welcome to Part 8 of our Pandas series, where we take a deep dive into advanced pandas techniques for working with data in Pandas. In this blog, we will explore essential skills that every data analyst or scientist should master when dealing with complex datasets.
In the world of data analysis, mastering Pandas is a crucial step towards becoming a proficient data handler. Whether you’re combining and reshaping data from multiple sources, managing categorical variables efficiently, or optimizing memory usage for large datasets, these advanced Pandas techniques are indispensable.
As we progress through this blog, you’ll discover the power of merging and joining DataFrames, efficiently combining and reshaping data, handling categorical data, and implementing memory optimization techniques. These skills will enable you to tackle real-world data challenges with ease and precision.
So, without further ado, let’s embark on our journey into the world of advanced Pandas techniques and enhance your data analysis capabilities. Whether you’re a seasoned data professional or just getting started, this blog has something valuable in store for you. Let’s begin!
In this section we will be discussing about merging and joining various DataFrames this is something everyone should master when dealing with advanced pandas techniques, so without further ado lets dive in.
Data merging is a fundamental operation in data analysis that involves combining data from multiple sources to create a comprehensive dataset. Whether you’re dealing with data from different departments in a company, multiple data files, or integrating external data sources, merging allows you to consolidate information for a more holistic view of the data. In this section, we’ll explore the significance of merging data and provide insights into common scenarios where data merging is necessary for effective analysis.
Combining Sales Data Consider a retail company that stores sales data in separate files for each store location. To gain an overview of the company’s total sales performance, you’ll need to merge these individual datasets into one.
Joining Customer Information When you want to analyze customer purchasing behavior in conjunction with demographic data, you’ll likely have customer information in one dataset and purchase history in another. Merging these datasets based on a unique customer identifier can provide valuable insights.
Incorporating External Data For more comprehensive analysis, you may need to incorporate external data sources such as economic indicators or weather information into your existing datasets. Merging these external data sources with your primary dataset can enrich your analysis.
Concatenating DataFrames is a powerful technique for combining data along rows. It’s useful when you have related data in separate DataFrames that share the same columns. Pandas provides the pd.concat() function to efficiently perform this operation. Let’s dive into how to use this function with examples and explore common use cases.
Combining Sales Data from Multiple Stores Suppose you have sales data stored in separate DataFrames for each store location. To consolidate these into one comprehensive sales dataset, you can use pd.concat(). This method is particularly handy when the column structure is the same across all DataFrames, and you need to stack them vertically.

Step 1: Data Separation Suppose we have sales data for two stores, Store A and Store B. Each store’s data is stored in separate DataFrames, namely store1_data and store2_data.
Step 2: Data Consistency Both store1_data and store2_data share the same column structure. This means that the columns, including ‘Store’, ‘Date’, and ‘Sales’, are identical. Having consistent column names and order is crucial when using pd.concat().
Step 3: Combining the Data We want to consolidate these separate DataFrames into one comprehensive sales dataset. To achieve this, we use the pd.concat() function, passing a list of DataFrames [store1_data, store2_data] as the first argument. The ignore_index=True parameter ensures that the index is reset in the resulting DataFrame.
Step 4: The Result After performing the concatenation, we have a single DataFrame named combined_sales that stacks the data from both Store A and Store B. It allows us to analyze the combined sales data conveniently.
This example showcases how you can use pd.concat() to efficiently merge DataFrames with the same column structure. It’s a handy method when dealing with data from various sources but with consistent data formats.
Combining Data with Different Columns Suppose you have two DataFrames with different sets of columns, and you want to combine them into one DataFrame, filling missing values with NaN.

Step 1: Data Separation Let’s say we have two DataFrames, dataframe_A and dataframe_B. Each of these DataFrames contains data, but the columns in dataframe_Aanddataframe_B` are not identical. This could be due to data collected from different sources or at different times, and they may have unique columns specific to their context.
Step 2: Identifying Common Columns Before merging these DataFrames, we need to identify common columns that are shared between both DataFrames. These are the columns where we can match and combine the data.
Step 3: Concatenation with pd.concat() We use the pd.concat() function to combine these DataFrames. However, since they have different columns, we set ignore_index=True to reset the index. This ensures that the new combined DataFrame has a continuous index.
Step 4: Handling Missing Values The resulting DataFrame, let’s call it combined_data, will have NaN values in places where the original DataFrames had different columns. These NaN values represent missing data in those columns.
Step 5: The Result By using pd.concat(), we’ve successfully combined data from dataframe_A and dataframe_B, even though they had different sets of columns. This approach is helpful when you need to merge data from multiple sources, and you’re comfortable with missing values represented as NaN.
In essence, this example illustrates how Pandas allows you to merge data from different sources, even when the column structure isn’t exactly the same.
pd.merge:When working with data, it’s common to have related data in separate DataFrames that you need to combine. The pd.merge() function in Pandas allows you to merge DataFrames based on specified key columns. This operation is analogous to SQL joins.
Step 1: Identifying Key Columns Before merging DataFrames, you need to identify the key columns that will serve as the basis for the merge. These key columns should have common values across the DataFrames, allowing Pandas to match and combine the data accurately.
Step 2: Merging Data The pd.merge() function takes several parameters, including the DataFrames to be merged and the key columns to merge on. You can also specify the type of join, which determines which rows are included in the merged DataFrame.
There are four common types of joins:
Step 3: Handling Missing Data After merging, the resulting DataFrame may contain missing data (NaN) in columns that didn’t have matching values. You can use techniques like .fillna() to handle missing data based on your analysis goals.
Merging Sales and Customer Data Imagine you have two DataFrames: one containing sales data and another containing customer information. You want to combine them to get a comprehensive view of sales with customer details. You can achieve this by merging these DataFrames based on a common customer ID.
Here’s an example using an inner join:
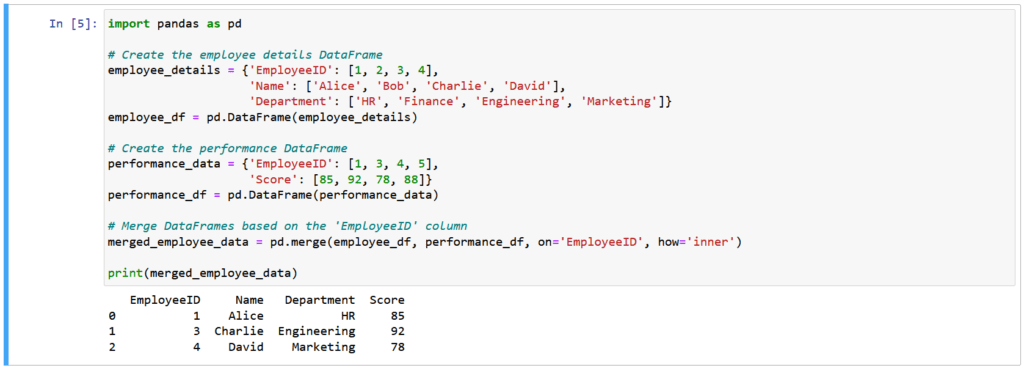
In this example, we’re merging employee details with performance data based on the common ‘EmployeeID’ column. The resulting DataFrame, merged_employee_data, provides a comprehensive overview of each employee’s performance, making it easier to analyze and report on HR-related insights. Whether you’re working with sales, HR, or any other domain, Pandas’ merging capabilities help you gain valuable insights by combining data from different sources.
In data analysis, combining data from different sources and reshaping it plays a pivotal role in gaining insights and making informed decisions. In this section, we’ll explore data combining techniques that help you stack and unstack data, enabling you to efficiently transform and manage your datasets. Whether you’re dealing with financial data, survey results, or any other information, Pandas’ capabilities for data reshaping and combining are essential for your data analysis toolbox.
We’ll delve into the methods for stacking and unstacking data, and we’ll showcase various scenarios where data reshaping becomes a crucial step in your data analysis process. By the end of this section, you’ll have a solid understanding of how to reshape and combine your data effectively using Pandas.
In this section, we’ll dive into the powerful techniques of stacking and unstacking data in Pandas. These operations allow you to transform your data, making it more suitable for specific analyses and presentations. By stacking and unstacking, you reshape your data, potentially making it more accessible and informative.
Stacking is essentially a process of pivoting the innermost level of column labels to create a new level of row indices. This operation is particularly useful when you have a multi-level column structure and you want to convert some of these columns into rows, providing a more organized format for analysis.
Let’s take a look at an example to understand stacking better. Suppose you have sales data with multi-level columns indicating sales figures for different products. By stacking this data, you can create a more straightforward representation where the product names become row indices.

Unstacking, on the other hand, reverses the process. It takes the innermost level of row indices and moves them back to become the innermost level of column labels. This operation is particularly handy when you have data in a hierarchical structure and you want to reorganize it for clarity.
Here’s an example: Imagine you have data where sales figures are indexed by products and months. By unstacking the product level, you can see monthly sales data for each product as separate columns, making it easier to compare and analyze.

Stacking and unstacking are crucial in various situations. For example, they are widely used in time series data, where you might need to pivot time-based indices for different analyses. Hierarchical data structures, like those encountered in financial or organizational datasets, can also benefit from these operations. Stacking and unstacking can make data more manageable, accessible, and interpretable.
Example: Stacking and Unstacking Time Series Data To provide a practical example, let’s consider time series data that is often presented in a stacked format. We will stack this data to transform it into a more structured format and then unstack it to revert to the original representation.

In this example, you can observe how stacking and unstacking allow us to efficiently handle time series data.
Stacking and unstacking are indispensable tools when it comes to data reshaping. By mastering these operations, you gain more control over your data and can tailor it to your specific analytical needs. Whether dealing with complex multi-level data or simplifying time series information, stacking and unstacking empower you to handle your data efficiently.
Data reshaping is a critical aspect of data analysis and preparation, particularly when working with complex datasets or aiming for a better presentation of information. Let’s explore some scenarios where data reshaping is crucial and how it can greatly enhance your data analysis process:
Suppose you have financial data with multiple levels of indexing. Unstacking the data can make it more manageable for in-depth analysis of each stock’s historical performance.When dealing with hierarchical or multi-level indexed data, reshaping becomes crucial for simplifying data access and improving clarity.
Example: For example, financial data with indices like stock symbols and dates can be challenging to work with in their raw form. By unstacking or stacking, you can restructure the data to focus on specific aspects, such as individual stock performance over time.
Time series data often comes in a stacked format, with dates as rows and different data points as columns. This arrangement can be less intuitive for analysis, as you may need to transpose the data to work with it efficiently. By unstacking the time series, you can easily compare data points across different time intervals.
Example: Let’s say you have daily stock prices over several years. Stacking this data can be beneficial when focusing on specific stocks’ performance over time, while unstacking can provide a clearer picture of how each stock compares daily.
Effective data visualization often requires data to be in a particular format. Reshaping can be essential to transform data into a format that best suits the chosen visualization method. For instance, stacked data might be suitable for certain types of charts, while unstacked data may work better for others.
Example: When creating a stacked area chart to display cumulative sales for different products over time, you’ll need to reshape your data to show products as separate columns and time as rows for a cleaner representation.
Datasets that represent hierarchical structures, such as organizational hierarchies, can benefit from reshaping. Stacking and unstacking can help drill down into specific aspects of the hierarchy, making it easier to analyze.
Example: You have employee data with a hierarchical structure, including department and team levels. Reshaping this data can allow you to focus on specific teams or departments for detailed analysis.
In each of these scenarios, data reshaping with tools like stacking and unstacking is crucial for making the data more accessible, improving clarity, and enhancing the efficiency of data analysis and presentation. By mastering these techniques, you’ll gain a valuable skill for handling diverse datasets in various domains, from finance to organizational data management to time series analysis and data visualization.
Data pivoting is a fundamental data reshaping technique that allows you to transform your data for improved analysis and reporting. It’s particularly valuable when dealing with long-format data that may not be intuitive for analysis or visualization. In this section, we’ll delve into the concept of pivoting data, exploring how it can uncover valuable insights hidden within your datasets. We’ll also learn how to pivot data effectively using Pandas’ pivot and pivot_table functions.
Data pivoting, often referred to as “wide-to-long” or “long-to-wide” transformation, involves restructuring your dataset by converting columns into rows or vice versa. This process enables you to:
Simplify Complex Data: Long-format data may have multiple columns representing various attributes, which can make analysis cumbersome. Pivoting can help by reshaping data into a more compact and structured form.
Facilitate Analysis: Certain analyses, like time series or categorical comparisons, are more straightforward when data is structured in a specific way. Pivoting helps you organize your data to match the analytical requirements.
Enhance Visualization: Visualization tools often expect data in a specific format. By pivoting your data, you can create visualizations more easily, making the information more accessible and understandable.
pivot and pivot_table:Pandas provides two primary methods for pivoting data:
pivot: This method pivots your data by specifying the index, columns, and values to create a new DataFrame. It is suitable for simple data transformations where you don’t need to aggregate values during the pivoting process.Example – Using pivot:

pivot_table: For more complex scenarios, where you need to aggregate data while pivoting, the pivot_table method is handy. It allows you to apply aggregation functions to duplicate entries. This function comes in handy when you have multiple values for the same index and columns.
pivot_table:
In the upcoming sections, we’ll explore both methods in greater detail with real-world examples, helping you master the art of data pivoting. By understanding when and how to pivot your data effectively, you’ll significantly enhance your data analysis capabilities and gain deeper insights from your datasets.
In the world of data analysis, the process of data reshaping is a crucial skill, allowing you to present data in various ways to suit specific analytical needs. One of the essential techniques for reshaping data is “melting.” Data melting transforms wide-format data into a more understandable, long-format structure. In this section, we will dive deep into the art of melting data using Pandas’ melt function and explore practical examples to reinforce your understanding.
Data melting is the process of transforming wide-format data into a long-format. It involves unpivoting or unstacking data, where columns become rows. This transformation allows for more efficient analysis, visualization, and modeling, particularly when dealing with multi-category data or time series.
melt Function:Pandas provides the melt function, which is a powerful tool for melting data. This function requires you to specify the columns to retain as identifiers (ID variables) and which columns to melt (value variables).
melt:
In the provided example, id_vars represent columns to keep as identifiers, var_name defines the name of the melted column representing categories, and value_name sets the name for the melted values column. The result is a long-format representation of data that’s often easier to work with for various analytical tasks.
In the forthcoming sections, we’ll walk through hands-on examples to demonstrate the power of data melting. By mastering this technique, you’ll become more versatile in handling and analyzing data, making you a more proficient data analyst.
Let’s dive into some practical examples to see the melt function in action.
Suppose you have a wide-format sales dataset where each month is a separate column. If you want to analyze this data, it’s often more convenient to melt it into a long-format structure, where each row represents a single sale with columns for the year, month, store (Sales_A, Sales_B, Sales_C), and sales value. You can do this using the melt function:
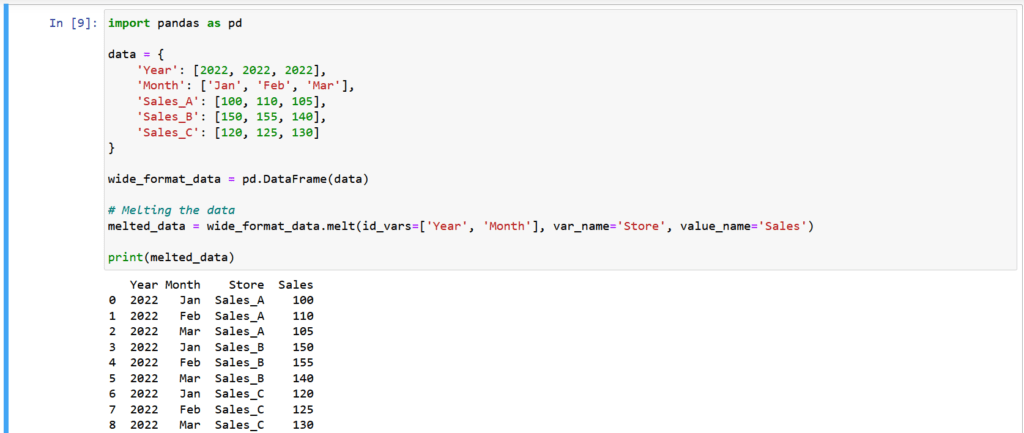
In the melted data, each row now represents a single sale, making it easier to perform various analyses and visualizations on this long-format dataset.
The melt function is particularly handy for handling wide-format data and reshaping it for specific analytical tasks.
Categorical data is a fundamental type of data that represents different categories, labels, or groups. These categories don’t have a numerical value but are used to label and classify data into specific groups. In data analysis, understanding and working with categorical data are essential, as it enables you to make sense of non-numeric information. In this section, we will explore what categorical data is, its significance in data analysis, and why handling it categorically is advantageous in Pandas.
Grouping and Aggregation: Categorical data is used to group and aggregate data based on common attributes. For instance, in a sales dataset, you can use product categories to group products for summary statistics like total sales by category.
Visualization: Categorical data is often used for labeling and coloring elements in data visualizations. This is crucial for creating clear and informative charts and graphs.
Efficiency: Categorical data reduces memory usage and speeds up operations compared to using text labels. Pandas provides efficient categorical data types that save memory and improve performance.
Pandas offers built-in support for handling categorical data, providing several advantages:
Improved Memory Usage: Categorical data types in Pandas are memory-efficient. They store data as integers, using a separate mapping of category labels to integers, reducing the memory footprint.
Faster Operations: Due to the internal representation as integers, operations on categorical data are faster than working with strings.
Data Integrity: Categorical data types can enforce data integrity by restricting the values to a predefined set of categories, preventing invalid entries.
Enhanced Grouping and Aggregation: Grouping and aggregation with categorical data are more meaningful. You can group data based on categories, making your analysis more intuitive.
In the following sections, we will delve into working with categorical data in Pandas and leverage these advantages for efficient and insightful data analysis.
Converting data to categorical type is a fundamental step in working with categorical data in Pandas. In this section, we will explore how to convert columns to categorical data types and highlight the memory and performance benefits associated with this process.
To convert columns to categorical data types in Pandas, you can use the .astype() method. This method allows you to specify the desired data type, such as ‘category’, for the columns you want to convert. Here’s an example of how to do this:

Converting data to categorical type offers several key advantages:
Reduced Memory Usage: Categorical data types in Pandas are memory-efficient. When you convert a column to categorical, Pandas stores the data more efficiently as integers, accompanied by a separate mapping of category labels to integers. This significantly reduces memory usage, making it ideal for large datasets.
Faster Operations: With data stored as integers, operations on categorical data are faster than those on string data. This translates to quicker data analysis, especially when you need to perform aggregations or filtering.
Data Integrity: Categorical data types can enhance data integrity. By defining a fixed set of categories, you can prevent invalid entries and ensure that your data adheres to predefined categories.
Enhanced Grouping and Aggregation: Categorical data types are particularly useful when you need to group and aggregate data. Grouping by categories becomes more efficient and meaningful, leading to more insightful analysis.
In the upcoming sections, we will explore practical examples of working with categorical data in Pandas, demonstrating how to take advantage of these benefits for data analysis.
In this section, we will delve into common operations with categorical data in Pandas. These operations include ordering categories and renaming categories to make the data more meaningful and organized. We will provide practical examples to demonstrate how to perform these operations effectively.
Ordering categories is a useful operation when you have categorical data that has a logical order or hierarchy. For example, days of the week or education levels can be logically ordered. To order categories, you can use the .set_categories() method. Let’s take a look at an example:

Renaming categories can be beneficial when you want to change the labels of categories to make them more descriptive. To rename categories, you can use the .rename_categories() method. Here’s an example:

By ordering and renaming categories, you can improve the clarity and organization of your categorical data, making it more insightful for analysis. In the following examples, we will demonstrate how these operations can be applied in real-world scenarios, emphasizing their importance in data analysis.
In this eighth installment of our Pandas series, we’ve explored advanced techniques for working with data in Pandas. We’ve learned about data merging, combining, and reshaping, all of which are essential skills for data professionals and analysts. These techniques empower us to organize and manipulate data effectively, whether it’s collected from multiple sources, needs to be combined into a cohesive dataset, or requires restructuring to reveal meaningful insights.
Furthermore, we’ve touched on the vital aspects of handling categorical data, such as converting data types and conducting operations to better understand the information we’re working with. This capability enriches our data analysis, helping us draw more accurate conclusions and make data-driven decisions.
Our journey through Pandas continues to expand your skills and toolkit for data manipulation and analysis. Stay tuned for more advanced topics in future installments, and remember to apply these techniques to real-world data scenarios, where their value becomes truly evident. If you enjoyed the blog follow 1stepgrow.




















We provide online certification in Data Science and AI, Digital Marketing, Data Analytics with a job guarantee program. For more information, contact us today!
Courses
1stepGrow
Terms
Anaconda | Jupyter Notebook | Git & GitHub (Version Control Systems) | Python Programming Language | R Programming Langauage | Linear Algebra & Statistics | ANOVA | Hypothesis Testing | Machine Learning | Data Cleaning | Data Wrangling | Feature Engineering | Exploratory Data Analytics (EDA) | ML Algorithms | Linear Regression | Logistic Regression | Decision Tree | Random Forest | Bagging & Boosting | PCA | SVM | Time Series Analysis | Natural Language Processing (NLP) | NLTK | Deep Learning | Neural Networks | Computer Vision | Reinforcement Learning | ANN | CNN | RNN | LSTM | Facebook Prophet | SQL | MongoDB | Advance Excel for Data Science | BI Tools | Tableau | Power BI | Big Data | Hadoop | Apache Spark | Azure Datalake | Cloud Deployment | AWS | GCP | AGILE & SCRUM | Data Science Capstone Projects | ML Capstone Projects | AI Capstone Projects | Domain Training | Business Analytics
WordPress | Elementor | On-Page SEO | Off-Page SEO | Technical SEO | Content SEO | SEM | PPC | Social Media Marketing | Email Marketing | Inbound Marketing | Web Analytics | Facebook Marketing | Mobile App Marketing | Content Marketing | YouTube Marketing | Google My Business (GMB) | CRM | Affiliate Marketing | Influencer Marketing | WordPress Website Development | AI in Digital Marketing | Portfolio Creation for Digital Marketing profile | Digital Marketing Capstone Projects
Jupyter Notebook | Git & GitHub | Python | Linear Algebra & Statistics | ANOVA | Hypothesis Testing | Machine Learning | Data Cleaning | Data Wrangling | Feature Engineering | Exploratory Data Analytics (EDA) | ML Algorithms | Linear Regression | Logistic Regression | Decision Tree | Random Forest | Bagging & Boosting | PCA | SVM | Time Series Analysis | Natural Language Processing (NLP) | NLTK | SQL | MongoDB | Advance Excel for Data Science | Alteryx | BI Tools | Tableau | Power BI | Big Data | Hadoop | Apache Spark | Azure Datalake | Cloud Deployment | AWS | GCP | AGILE & SCRUM | Data Analytics Capstone Projects
Bangalore:
Anjanapura | Arekere | Basavanagudi | Basaveshwara Nagar | Begur | Bellandur | Bommanahalli | Bommasandra | BTM Layout | CV Raman Nagar | Electronic City | Girinagar | Gottigere | Hebbal | Hoodi | HSR Layout | Hulimavu | Indira Nagar | Jalahalli | Jayanagar | J. P. Nagar | Kamakshipalya | Kalyan Nagar | Kammanahalli | Kengeri | Koramangala | Kothnur | Krishnarajapuram | Kumaraswamy Layout | Lingarajapuram | Mahadevapura | Mahalakshmi Layout | Malleshwaram | Marathahalli | Mathikere | Nagarbhavi | Nandini Layout | Nayandahalli | Padmanabhanagar | Peenya | Pete Area | Rajaji Nagar | Rajarajeshwari Nagar | Ramamurthy Nagar | R. T. Nagar | Sadashivanagar | Seshadripuram | Shivajinagar | Ulsoor | Uttarahalli | Varthur | Vasanth Nagar | Vidyaranyapura | Vijayanagar | White Field | Yelahanka | Yeshwanthpur
Other Top Cities:
Mumbai | Pune | Nagpur | Delhi | Gurugram | Chennai | Hyderabad | Coimbatore | Bhubaneswar | Kolkata | Indore | Jaipur and More