Significance of Pandas in Time Series Analysis:
Pandas is a versatile and widely-used library in the field of data analysis and manipulation, and its significance becomes even more pronounced when it comes to handling and analyzing time-based data. Here are some key reasons why Pandas is essential for working with time series data:
Efficient Data Structures:
Pandas provides data structures like Series and DataFrame, which are highly optimized for time series operations. These structures allow for easy organization, manipulation, and analysis of time-based data.
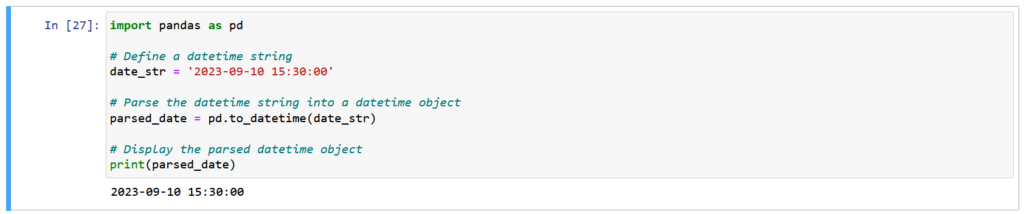
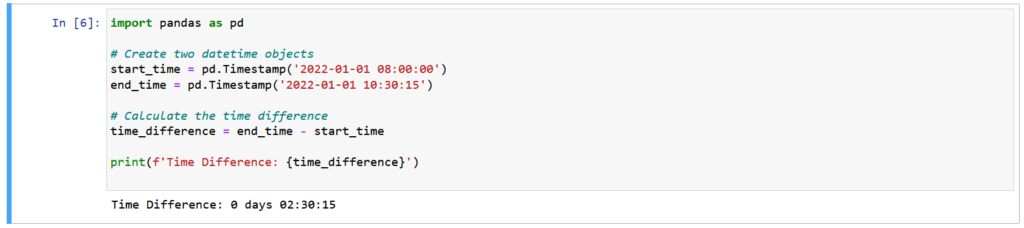
Pandas has robust support for datetime objects, making it effortless to work with dates and times. It provides powerful functions for parsing, formatting, and performing arithmetic operations on datetime data.
Resampling and Frequency Conversion:
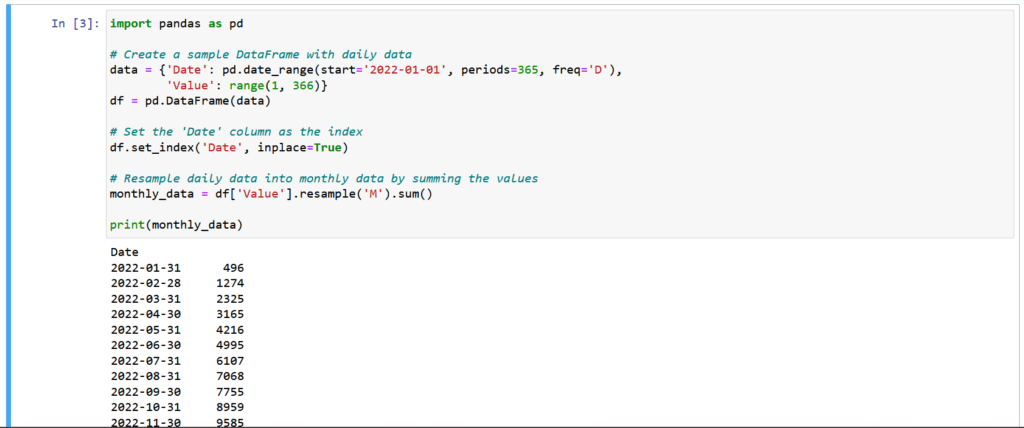
Pandas offers resampling methods that simplify tasks like downsampling (reducing data to a lower frequency) and upsampling (increasing data to a higher frequency). This is crucial for aligning data with different time frequencies.
Time series often require rolling statistics like moving averages or rolling sums to identify trends and patterns. Pandas provides convenient rolling window operations for this purpose.
In Pandas, you can set datetime columns as the index of a DataFrame, allowing for efficient time-based slicing, filtering, and grouping.
Pandas integrates seamlessly with visualization libraries like Matplotlib and Seaborn, enabling the creation of insightful time series plots and charts.
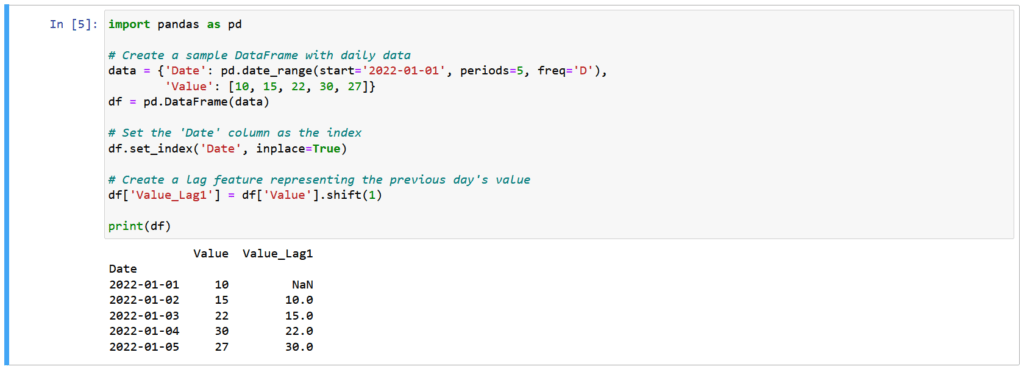
Time-based data often needs transformation, such as shifting or differencing to make it stationary for analysis. Pandas offers functions for these operations.
Handling missing values is common in time series data. Pandas provides methods to interpolate or fill missing data points accurately.
Pandas can align data from different sources based on timestamps, making it easier to combine and analyze datasets from various origins.
In summary, Pandas simplifies the complexities of times and dates, making it accessible to data analysts, scientists, and engineers. Its comprehensive functionality, efficient data structures, and seamless integration with other Python libraries make it an indispensable tool for anyone working with time-based data analysis.